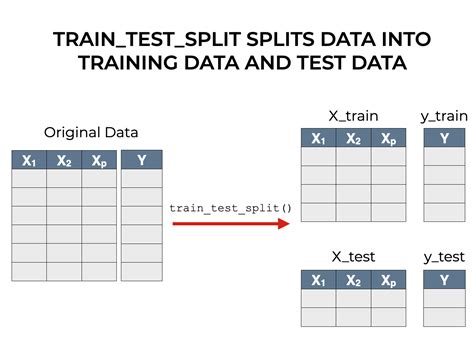
python train_test_split drop 2 features|random state 42 in train test split : distribution In this tutorial, you’ll learn how to split your Python dataset using Scikit-Learn’s train_test_split function. You’ll gain a strong understanding of the importance of splitting your data for machine learning to avoid underfitting or .
WEB10 MELHORES Sapateiros em Fortaleza, CE, encontre informações, telefones, endereços, mapa como chegar e muito mais no GuiaTelefone
{plog:ftitle_list}
Resultado da 2 de out. de 2022 · Os personagens do Free Fire desempenham um papel vital no campo de batalha, pois possuem habilidades valiosas que ajudam os usuários a superar facilmente seus oponentes. Os usuários podem equipar um máximo de quatro habilidades de personagem simultaneamente. .
I'm currently trying to train a data set with a decision tree classifier but I couldn't get the train_test_split to work. From the code below CS is the target output and EN SN JT FT .Split arrays or matrices into random train and test subsets. Quick utility that wraps input validation, next(ShuffleSplit().split(X, y)), and application to input data into a single call for .
In this tutorial, you’ll learn: Why you need to split your dataset in supervised machine learning. Which subsets of the dataset you need for an unbiased evaluation of your model. How to use train_test_split() to split your . Train Test Split Using Sklearn. The train_test_split () method is used to split our data into train and test sets. First, we need to divide our data into features (X) and labels (y). . Learn how to split sklearn datasets with the `train_test_split` function. Featuring examples for similar tools such as numpy and pandas!
In this tutorial, you’ll learn how to split your Python dataset using Scikit-Learn’s train_test_split function. You’ll gain a strong understanding of the importance of splitting your data for machine learning to avoid underfitting or . In Python, train_test_split is a function in the model_selection module of the popular machine learning library scikit-learn. This function is used to perform the train test split procedures, which splits a dataset into two . We’re going to use a couple of libraries in this article: pandas to read the file that contains the dataset, sklearn.model_selection to split the training and testing dataset, and matplotlib to.
In this example, the train_test_split function is used to split the data into train and test sets. The stratify parameter is set to a DataFrame containing the ‘label’ and ‘category’ . Stack Overflow for Teams Where developers & technologists share private knowledge with coworkers; Advertising & Talent Reach devs & technologists worldwide about your product, service or employer brand; OverflowAI GenAI features for Teams; OverflowAPI Train & fine-tune LLMs; Labs The future of collective knowledge sharing; About the company . #importing libraries from sklearn.datasets import load_boston import pandas as pd import numpy as np import matplotlib import matplotlib.pyplot as plt import seaborn as sns import statsmodels.api as sm .
from sklearn.model_selection import train_test_split . There are a couple of arguments we can set while working with this method - and the default is very sensible and performs a 75/25 split. In practice, all of Scikit-Learn's .
train test split python example
random_state just sets the seed for the random number generator, which in this case, determines how train_test_split() shuffles the data.. Using random_state makes the results of our code reproducible.. Additionally, the argument value that we use is somewhat arbitrary. It doesn’t really matter if you set random_state = 0 or random_state = 322310, or any other value. I'm currently trying to train a data set with a decision tree classifier but I couldn't get the train_test_split to work. From the code below CS is the target output and EN SN JT FT PW YR LO LA are features input.Thanks @MaxU. I'd like to mention 2 things to keep things simplified. First, use np.random.seed(any_number) before the split line to obtain same result with every run. Second, to make unequal ratio like train:test:val::50:40:10 use [int(.5*len(dfn)), int(.9*len(dfn))].Here first element denotes size for train (0.5%), second element denotes size for val (1-0.9 = 0.1%) and . Scikit learn plays really well with Pandas, so I suggest you use it. Here's an example: In [1]: import pandas as pd import numpy as np from sklearn.model_selection import train_test_split data = np.reshape(np.random.randn(20),(10,2)) # 10 training examples labels = np.random.randint(2, size=10) # 10 labels In [2]: # Giving columns in X a name X = .
If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to keep track of the indices (remember to fix the random seed to make everything reproducible):. import numpy # x is your dataset x = numpy.random.rand(100, 5) numpy.random.shuffle(x) training, test = x[:80,:], x[80:,:] In this article, let's learn how to do a train test split using Sklearn in Python. Train Test Split Using Sklearn The train_test_split() method is used to split our data into train and test sets. First, we need to divide our data into features (X) and labels (y). The dataframe gets divided into X_train,X_test , y_train and y_test. X_train and y_tra
You can simply do it with train_test_split() method available in Scikit learn: from sklearn.model_selection import train_test_split train, test = train_test_split(X, test_size=0.25, stratify=X['YOUR_COLUMN_LABEL']) I have also prepared a short GitHub Gist which shows how stratify option works:
The Basics: Sklearn train_test_split. The train_test_split function is a powerful tool in Scikit-learn’s arsenal, primarily used to divide datasets into training and testing subsets. This function is part of the sklearn.model_selection module, which contains utilities for splitting data. But how does it work? Let’s dive in. from sklearn.model_selection import train_test_split . Rooms Type Method Bathroom 0 2 h S 1.0 1 2 h S 1.0 2 3 h SP 2.0 3 3 h PI 2.0 4 4 h VB 1.0 Before split -- Method feature distribution S 0.664359 SP 0.125405 PI 0.115169 VB 0.088292 SA 0.006775 Name: Method, dtype: float64 Before split -- Type feature distribution h 0.695803 u 0.222165 t 0.082032 Name: Type, dtype: float64 After split -- Method . Here is an example: import numpy as np import pandas as pd from sklearn.model_selection import train_test_split # create dummy data with unbalanced feature value . What Is the Train Test Split Procedure? Train test split is a model validation procedure that allows you to simulate how a model would perform on new/unseen data. Here is how the procedure works: Train test split procedure. | Image: Michael Galarnyk . 1. Arrange the Data. Make sure your data is arranged into a format acceptable for train test .
>>> x_test.shape (104, 12) The line test_size=0.2 suggests that the test data should be 20% of the dataset and the rest should be train data. With the outputs of the shape() functions, you can see that we have 104 rows in the test data . why do we drop target/label before splitting data into test and train? for example in code below. X = df.drop('Scaled sound pressure level',axis=1) y = df['Scaled sound pressure level'] split the data. from sklearn.model_selection import train_test_split 80/20 split by fixing the seed to reproduce the results Now that we are familiar with the train-test split model evaluation procedure, let’s look at how we can use this procedure in Python. Train-Test Split Procedure in Scikit-Learn. The scikit-learn Python machine learning . import pandas as pd from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split # Load dataset data = load_iris X = pd. . We'll use SelectKBest with the chi-square test to select the top 2 features. Python. from sklearn.feature_selection import SelectKBest, chi2 # Apply SelectKBest with chi2 .
It is not actually difficult to demonstrate why using the whole dataset (i.e. before splitting to train/test) for selecting features can lead you astray. Here is one such demonstration using random dummy data with Python and scikit-learn: import numpy as np from sklearn.feature_selection import SelectKBest from sklearn.model_selection import .W3Schools offers free online tutorials, references and exercises in all the major languages of the web. Covering popular subjects like HTML, CSS, JavaScript, Python, SQL, Java, and many, many more.
Isn't that obvious? 42 is the Answer to the Ultimate Question of Life, the Universe, and Everything.. On a serious note, random_state simply sets a seed to the random generator, so that your train-test splits are always deterministic. If you don't set a seed, it is different each time. Relevant documentation:. random_state: int, RandomState instance or None, optional . test_size: This parameter represents the proportion of the dataset that should be included in the test split. The default value for this parameter is set to 0.25, meaning that if we don’t specify the test_size, the resulting split consists of 75% train and 25% test data.scikit learn train_test_split with 2 features. Ask Question Asked 7 years, 4 months . import pandas as pd import numpy as np X = orders.Text y = orders.CTR from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1) from sklearn.feature_extraction.text import CountVectorizer . ### Split the dataset into a set of features (X) and Target variable (y) import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.linear_model import LinearRegression from sklearn.linear_model import HuberRegressor from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split y .
To properly evaluate the accuracy with train_test_split, we split the model into a training (e.g. 60%) and testing set (e.g. 40%), train the model on the former subset and evaluate the performance on the latter. Train Test Split in Python. In Python, train_test_split is a function from the model_selection module of the Scikit-learn library. It . Photo by Markus Winkler from Pexels. Machine Learning is teaching a computer to make predictions (on new unseen data) using the data it has seen in the past. Machine Learning involves building a .
When fitting machine learning models to datasets, we often split the dataset into two sets:. 1. Training Set: Used to train the model (70-80% of original dataset) 2. Testing Set: Used to get an unbiased estimate of the model performance (20-30% of original dataset) In Python, there are two common ways to split a pandas DataFrame into a training set and .
train test split python documentation
WEBBuild yourself a monster girl harem! Tiny Devil Studio. Role Playing. The Making of Late Night Delivery 2! - Interactive Art Pack. $1. A short bonus behind-the-scenes about the .
python train_test_split drop 2 features|random state 42 in train test split